
软件截图
软件介绍
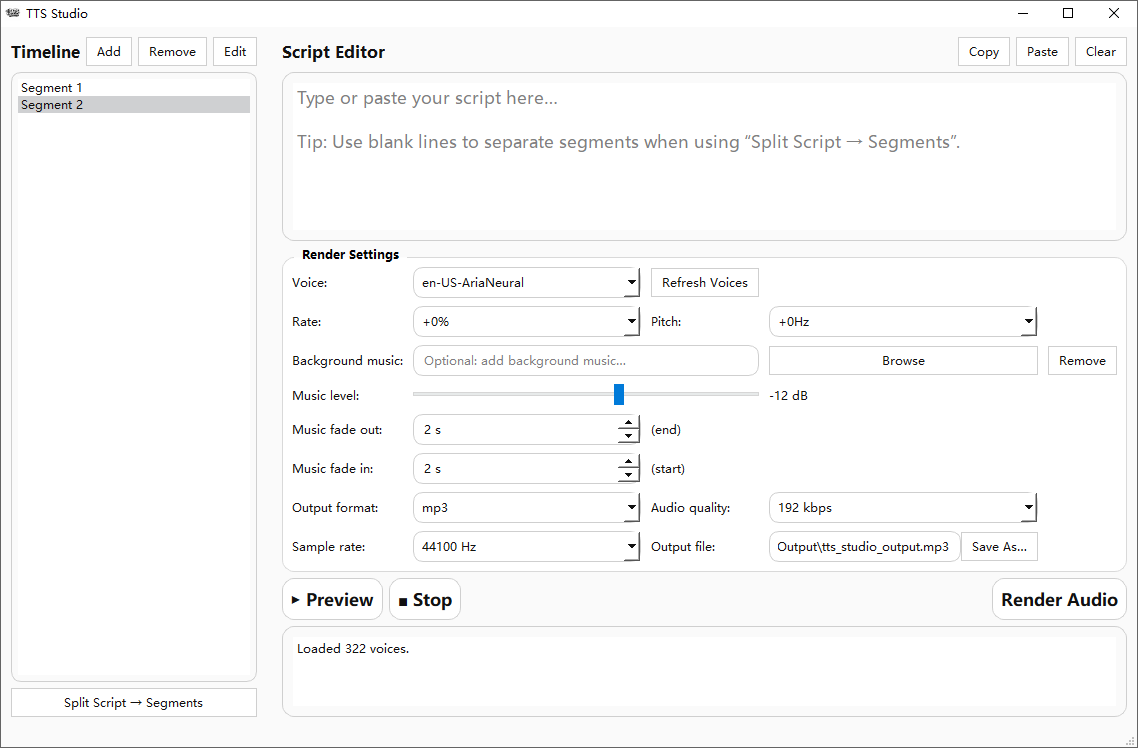
Text to Speech Studio (TTS Studio) 是一款专为高效音频生成而设计的桌面端文本转语音应用程序。在云端 AI 语音大行其道的当下,该软件反其道而行之,强调核心的本地化处理与隐私保护,确保用户的文稿与音频数据不会被上传至云端或被滥用。软件采用极为现代且直观的操作界面,将专业的音频混流技术与简化的操作逻辑相结合,用户只需输入脚本即可在几秒钟内渲染出高质量的拟真音频,是自媒体工作者与辅助内容创作者的高效辅助利器。
核心功能
拟真语音合成:内置多种高质量的声音模型,能够生成咬字清晰、语调逼真的自然语音,拒绝传统机械式的生硬朗读感。
多轨背景音混流:原生支持导入外部音频作为背景音乐(BGM)。用户不仅可以调整独立音轨的音量层级,还能一键应用平滑的淡入、淡出效果,实现人声与背景音的完美融合。
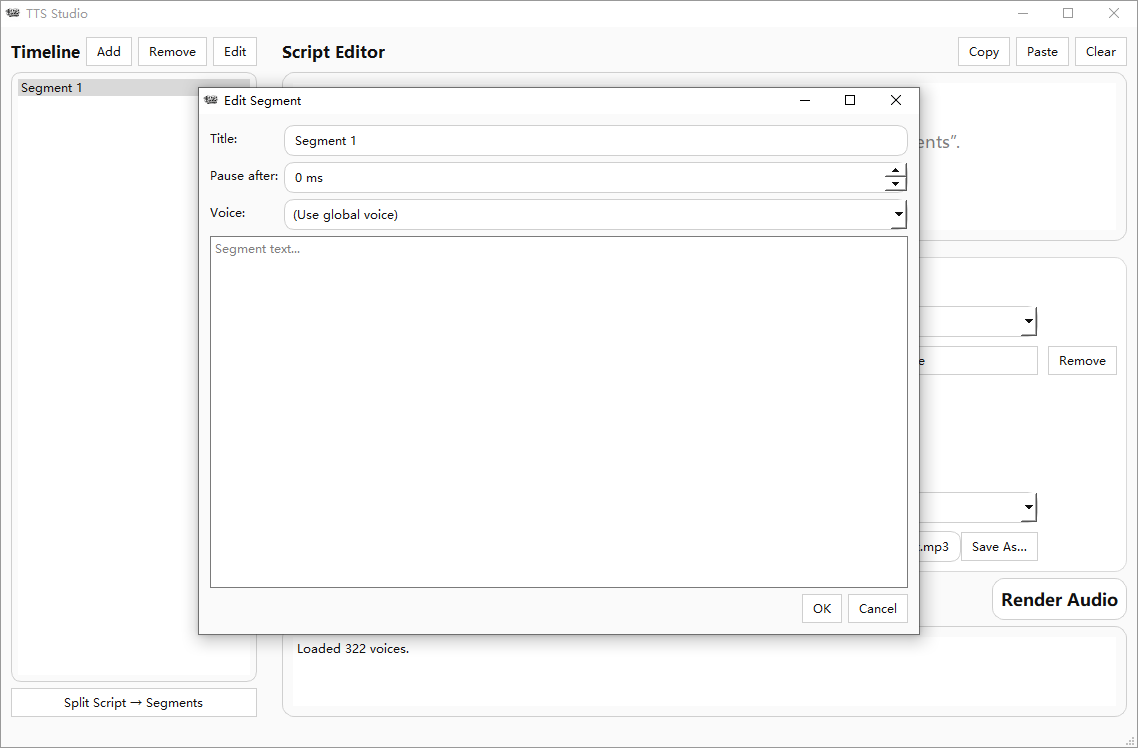
分段式时间线管理:区别于传统软件的“一镜到底”,TTS Studio 允许将长篇脚本切割成多个独立片段。用户可单独编辑某一部分文本,并自定义段落间的停顿延迟(Delay),从而创造出极其自然的呼吸感与演讲节奏。
实时预览与灵活导出:支持在执行最终渲染前即时试听音频效果,避免反复导出试错。成品支持以多种主流音频格式和质量级别导出,并自动归档至桌面专属目录,便于工程化管理。
适用人群
需要快速制作视频画外音与旁白的自媒体内容创作者(如B站、抖音、YouTube博主)。
负责企业内部培训课件、产品演示及说明书配音的媒体制作人员。
专注于播客(Podcast)制作或辅助视听内容研发的独立开发者。
对文本隐私要求极高,排斥云端 API 上传的文案创作者与商业用户。
优缺点分析
优点:
隐私优先:彻底的本地化处理机制,不收集、不存储任何文本及音频文件,为商业机密文案提供物理级隔离保障。
掌控力强:分段处理与时间线逻辑为声音的节奏(Timing)提供了极高颗粒度的微调空间。
开箱即用:界面极为简洁,没有冗余的参数配置墙,学习成本极低,适合快速迭代流水线作业。
缺点:
受限于本地引擎:由于主打本地生成,其声音库的多样性与情感表达上限,一定程度上受制于 Windows 系统内置的 TTS 引擎或本地语音包,无法完全媲美顶级云端大模型(如 Azure/ElevenLabs)的拟真度。
高阶处理匮乏:缺乏复杂的音频均衡器(EQ)调节、混响添加及多角色对话实时切换等高级宿主软件(DAW)功能。
系统要求
操作系统:Windows 10 / 11(推荐更新至最新版本以获取最佳的本地语音包支持)。
处理器:现代 1.5 GHz 或更快的双核处理器。
内存:至少 2 GB RAM(处理超长脚本及高频预览时,建议 4 GB 及以上)。
存储空间:约 200 MB 可用磁盘空间(不包含导出的高保真音频文件占用)。
获取途径:可通过 Microsoft Store(微软应用商店)直接安装与部署。
下载地址
声明:本站为非盈利性技术交流平台。所有资源均来自互联网或官方发布,版权归原作者所有。如有侵犯您的权益,请联系我们(fzxzcopy@163.com),我们将第一时间处理。