
软件截图
软件介绍
简繁通转换大师(OpenCC-DocxConverter)是由独立开发者维护的一款基于 Python 和著名开源项目 OpenCC 打造的跨平台简繁体中文字体转换 GUI 软件。在过去的文字处理流中,用户常面临使用 Word 自带转换功能造成的区域惯用语生硬直翻问题,抑或是使用网页工具导致原始文档排版、字幕时间轴完全丢失的尴尬。这款工具正是为了解决“排版无损”与“词汇本土化”两大痛点而生,不仅内置了图形化界面(基于 PySide6 构建),还整合了结巴分词(Jieba)引擎与多编码检测,确保转换结果在文面上不仅是“字符替换”,更贴合当地真实的中文阅读习惯。
核心功能
多维度的中文标准转译矩阵
不再局限于单纯的简繁互选,软件内置了高达 17 种语言文字转换模式。横向涵盖中国大陆《通用规范汉字表》标准、台湾正体、香港繁体之间的互转;深度支持词汇级别的港台本土化映射(如将大陆的“鼠标”智能等效为台湾的“滑鼠”),甚至支持日文旧字体与新字体的替换。富文本格式原生继承与无损保护
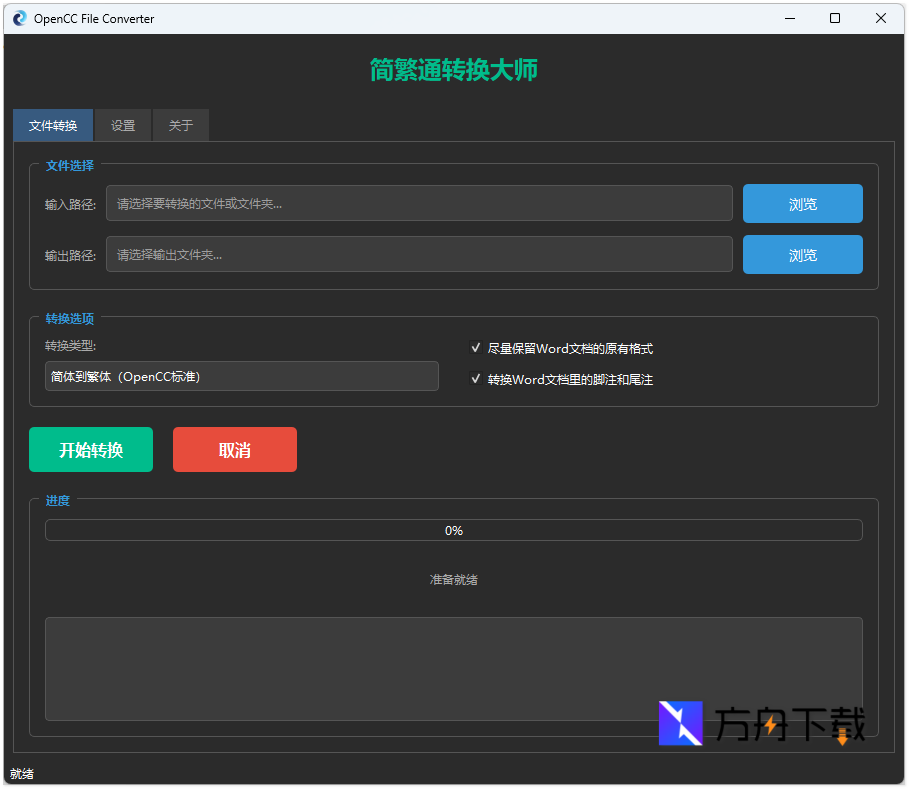
专门针对 Microsoft Word(.docx)处理算法进行了逻辑隔离,能在改变正文内容的同时,一比一保留原有字体大小、加粗斜体颜色等属性排版,连复杂的页眉页脚、脚注尾注、甚至是表格内的潜置文本均能有效涵盖。媒体外挂字串专项处理
针对影视汉化及压制组等重度用户,不仅支持常见的纯文本 TXT,更在算法上隔离了 SRT / ASS / SSA 字幕文件的时间控制码和渲染样式标签(如{...}和[mm:ss.xx]),确保转换不造成播放器解析错误。结巴分词(Jieba)智能预处理
为避免诸如“头发”与“发现”中“发”字的繁体多音字/多字型误选,利用结巴分词预载了现代及古汉语专项词典模块。在进行转换前先根据上下文将语句切分提纯,再喂入 OpenCC 引擎极大提升了长文本转换语境精准度。
适用人群
网文及电子书出海/引流编辑:需要将海量大陆网络文学快速转推至港澳台市场,需兼顾两区成语和网络词汇差别的出版从业者。
字幕组及影视压制创作者:需要在不破坏外挂字幕特效标签(ASS特效流)的前提下,一键生成简繁“双语/多轨”字幕的压制后期。
法务、版权及行政助理:针对两岸三地频繁的商业往来,需保障合同原排版样式完美无损的大量公文流转人员。
优缺点分析
优点:
强悍的隐私及本地处理保障:不依赖任何形式的云端 API 或网络节点连通,千字万字的涉密文档彻底锁死限制于本地 CPU 内部处理,信息绝对防漏。
智能化字符自动辨识处理:内置了
Chardet探针库,扔进去的乱码 TXT(无论是 GBK、GB2312 还是 UTF-8),均可自适应解码并在转换结束后重塑编码框,免去预转码折磨。批量并发高:支持整个底层文件夹直接投递处理,极大削减手工点击复选的时间成本。
缺点:
大型长篇文档存在性能瓶颈:受限于 Python 的解释器效能及分词前置运算开销(尤为开启 Jieba 词典之后),面对动辄数十兆或上千页含图表的 DOCX,会出现肉眼可见的卡顿期。
旧格式孤立:现版本通过基于 OpenXML 接口解析,故不可处理微软2003及更早版本的闭源
.doc二进制文档,需用户手工另存为.docx后方可使用。
系统要求
首选支持平台:作者提供提供开箱即用的便携分发压缩包,原生支持 Windows 10 及 Windows 11 环境直接运行。
脚本层泛适配要求:具备 Python 环境管理能力的进阶用户,可通过部署 Python 3.8+ 并克隆需求库,在 macOS(包括 Intel 与 Apple Silicon)架构及主流 Linux 发行版中手动编译出图形级或终端跑动界面。
硬件配置建议:仅由于需装载多套汉字字形树与巨量结巴词库进入内存演算,推荐宿主机具备 4GB 以上的随机访问内存(RAM)以维持程序防崩溃边界。
下载地址
声明:本站为非盈利性技术交流平台。所有资源均来自互联网或官方发布,版权归原作者所有。如有侵犯您的权益,请联系我们(fzxzcopy@163.com),我们将第一时间处理。