
软件截图
软件介绍
Vovsoft Audio to Lyrics Converter 是一款由 Vovsoft 开发的专为 Windows 用户设计的自动化音频转文本工具。在高度依赖云端 API 进行语音识别的当下,该软件最大的亮点在于其主打“完全离线”的 AI 推理架构。它巧妙地内置了 OpenAI 的 Whisper 语音识别模型,利用用户的本地硬件算力来“聆听”音轨,并将人声或歌唱内容精准提取为文本。由于所有的分析与转录过程都在本地机器上完成,用户不仅无需支付昂贵的云端 API 订阅费用,更能确保私密录音、未公开播客或机密采访数据的绝对隐私安全。
核心功能
离线 AI 转录引擎:集成 OpenAI Whisper 的本地模型。软件允许用户根据自身的硬件配置在多种模型级别(Base, Small, Medium, Large)中进行选择,通过多核 CPU 加速支持,在转录速度与识别精度之间取得最佳平衡。
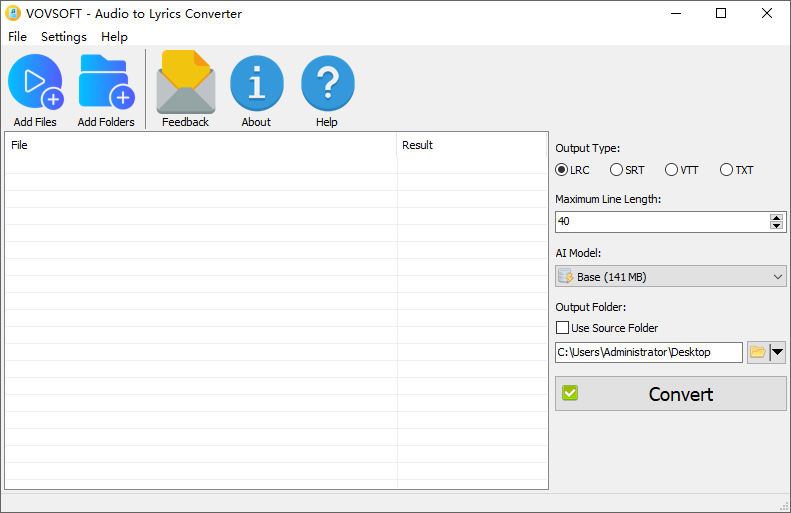
多格式文件导出:生成的转录文本可以导出为多种标准格式,包括用于音乐播放器的同步歌词文件 (LRC)、用于视频剪辑的字幕文件 (SRT/VTT) 以及用于纯阅读的文本文件 (TXT)。
精准时间轴同步:软件在识别音频的同时,会自动生成精确到毫秒级的时间戳标签(例如
[00:26.00]),确保最终输出的字幕或歌词与原始音轨的节奏完美对齐。自定义单行长度限制:为了适配不同尺寸的屏幕和多媒体播放器,用户可以设定每行文本的最大字符数,确保生成的字幕排版美观且易于阅读。
批处理与格式兼容:原生支持 MP3、WAV、OGG 和 FLAC 等主流音频格式。通过直观的拖拽操作,用户可以一次性导入整个文件夹并放入处理队列,实现多条音频的无人值守批量转换。
适用人群
需要为个人数字音乐库或卡拉OK设备制作精准同步 LRC 歌词的音乐爱好者。
需要将播客录音、会议记录、长篇采访离线转换为文字稿的媒体工作者与文案编辑。
为 YouTube 等社交媒体平台制作视频,且迫切需要批量生成准确 SRT/VTT 字幕的视频创作者。
处理敏感音频资料,禁止将数据上传至公有云进行在线语音识别的专业人士。
优缺点分析
优点:
绝对的数据隐私:100% 本地离线处理,无需网络连接,从根本上消除了数据泄露的风险。
免除订阅焦虑:采用一次性买断制(或免费试用),免除了长期调用云端语音识别 API 产生的高昂按量计费。
配置门槛极低:不同于 GitHub 上需要复杂命令行环境配置的开源 Whisper 项目,该软件提供了开箱即用的图形化界面。
缺点:
硬件算力依赖:由于在本地运行 AI 模型,特别是选择 Medium 或 Large 级高精度模型时,对电脑的 CPU 性能要求较高,老旧机型可能面临处理耗时过长的问题。
安装包体积庞大:为了包含完整的 AI 推理环境和模型库,软件的安装包和便携版体积(超过 130MB)相对一般的文本转换工具而言显得较为臃肿。
系统要求
操作系统:Windows 10 / Windows 11(仅支持 64 位版本)。
处理器:强烈建议配备支持现代多线程指令集的 Intel 或 AMD 多核处理器(如 Core i5/Ryzen 5 或以上级别),以加速本地 AI 模型推理速度。
内存:最低 4 GB RAM(若运行更高精度的 Whisper 模型,建议配置 8 GB - 16 GB 或以上内存以避免系统卡顿)。
存储空间:至少 200 MB 以上的可用磁盘空间(建议安装在 SSD 固态硬盘中以加快模型加载速度)。
下载地址
声明:本站为非盈利性技术交流平台。所有资源均来自互联网或官方发布,版权归原作者所有。如有侵犯您的权益,请联系我们(fzxzcopy@163.com),我们将第一时间处理。