
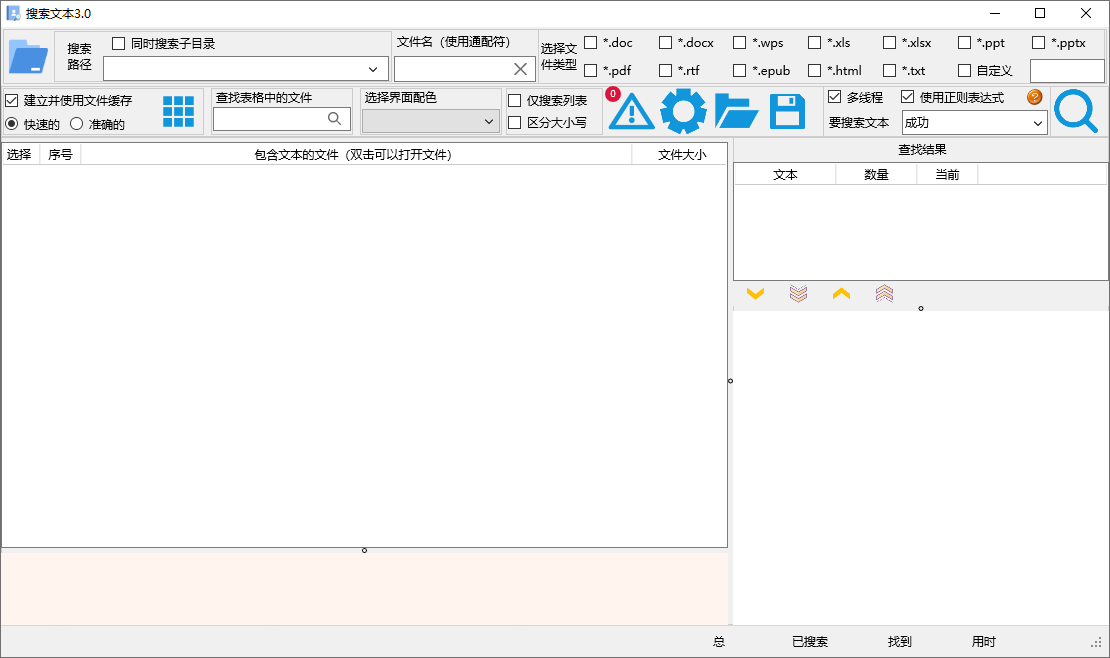
软件截图
软件介绍
搜索文本(FindTxt)是由开发者 tuao 编写的一款轻量级本地文档内容检索工具。与传统仅依靠文件名匹配的搜索软件不同,该软件专攻于“文件内部文字”的深度挖掘。凭借其底层的多线程调度优化与 NTFS 文件系统缓存机制,它能够在海量且格式各异的文档库中,利用普通字符或复杂的正则表达式,精准定位包含目标文本的特定文件与段落。最新发布的 v3.0 版本已全面升级为 64 位架构,大幅提升了极端情况下的稳定性与解析速度。
核心功能
全格式文档解析:原生支持跨越纯文本与富文本及专有格式的解析。不仅支持
*.txt、*.html,更能深度穿透 Office 家族(*.doc/docx,*.xls/xlsx,*.ppt/pptx)、PDF、RTF 乃至 EPUB 电子书,提取内部文本。多线程并发检索:在执行大规模目录扫描时,软件允许根据处理器核心数自动或手动分配最大线程数量(例如 4 核 8 线程的 CPU 将全速利用 8 个线程),大幅榨干硬件性能以加速文件流读取。
正则表达式支持:针对高级用户,内置了基于正则表达式的匹配引擎。无论是提取特定格式的身份证号、手机号、邮箱,还是模糊匹配代码日志片段,均能以极简的逻辑规则实现高维度的精准检索。
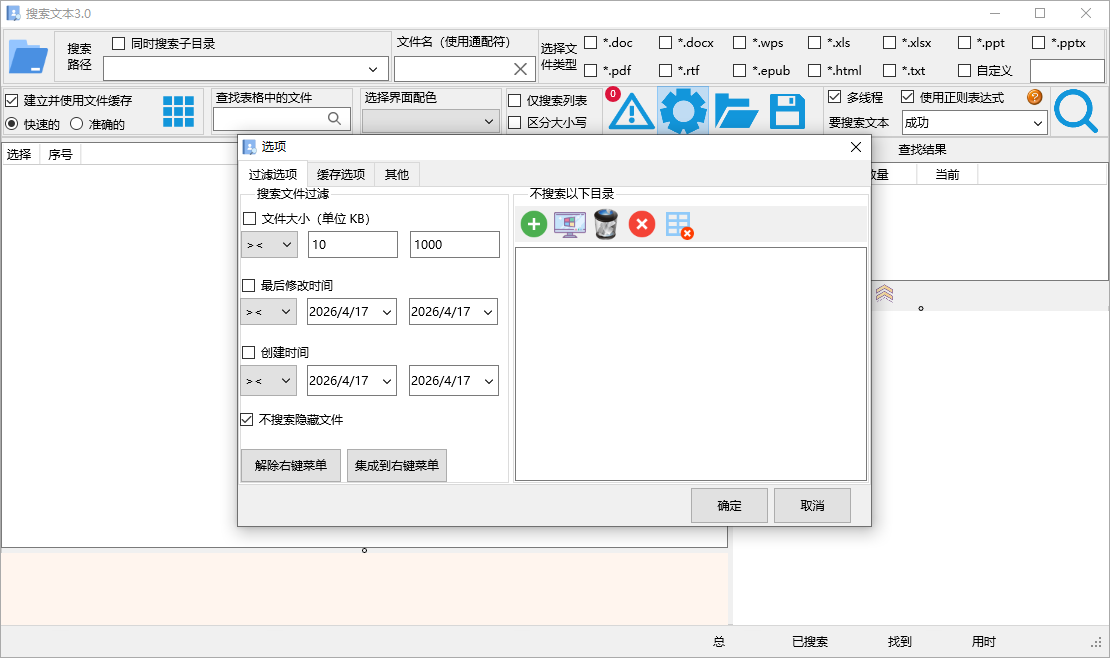
智能文件缓存机制:针对需反复查询的海量文件,提供基于 NTFS 磁盘特性的“快速方式”建立列表缓存。首次扫描耗费数秒至数分钟建立索引后,后续在同目录下的检索速度将呈现指数级跃升。
精准导航与预览:搜索结果列表支持结果统计并双击直达。双击“包含文本数量”列可跳转至文件内的首个结果,后续操作可逐个追踪到每一处被匹配到的上下文位置。
适用人群
文字工作者与法务行政:需要在常年积累的合同库或历史文档库(Word/PDF)中,快速翻找某个具体条款、人名或数据细节的办公人员。
程序员与系统运维:需要批量排查散落于复杂目录层级中的 Log 日志文件、利用扩展名过滤排查代码缺陷(Bug)的技术开发者。
科研学者与考研党:面对庞大的 PDF 文献库与 EPUB 电子书库,急需建立本地内容检索方案以验证引用的用户。
优缺点分析
优点:
深度穿透能力:完美填补了操作系统自带搜索对 PDF 及特定旧版 Office 文件格式(如
.doc)内容检索极度缓慢甚至失效的痛点。免安装高内聚:完全本地化处理,无需将机密文档上传至云端解析;且通过减少外部 DLL 依赖的独立编译方式,极大地增强了在不同 Windows 环境下的兼容性。
高度定制化过滤:支持通配符、特定扩展名组合(如输入
.inc,.pas,.bat)等多重文件过滤条件叠加,有效剔除无效 I/O 开销。
缺点:
UI 界面极客化:采用标准的系统原生控件布局,缺乏现代化的视觉设计,初次上手时密集的功能勾选项可能存在一定的认知负担。
冷启动检索性能开销:在未建立缓存且采取“准确方式”进行全盘富文本(特别是巨型 PDF 或 PPTX)内容解析时,由于需要实时解包和读取文件流,受限于硬盘物理读取速度,耗时相对较长。
系统要求
操作系统:Windows 7 / 8 / 10 / 11(自 v3.0 起已编译为原生 64 位版本,不再兼容 32 位操作系统环境)。
处理器 (CPU):强烈建议使用支持超线程技术的多核处理器(如 Intel Core i5 或 AMD Ryzen 5 及以上),以发挥多线程检索的最大并发优势。
内存 (RAM):建议 4 GB 及以上物理内存。在开启多线程处理大量庞大的 PDF 或 EPUB 文档时,瞬时内存占用会随之攀升。
磁盘环境:强烈推荐使用 NTFS 格式的固态硬盘(SSD)。在 FAT32 或机械硬盘(HDD)环境下,文件缓存的建立与读取速度将出现断崖式下跌。
下载地址
声明:本站为非盈利性技术交流平台。所有资源均来自互联网或官方发布,版权归原作者所有。如有侵犯您的权益,请联系我们(fzxzcopy@163.com),我们将第一时间处理。