
软件截图
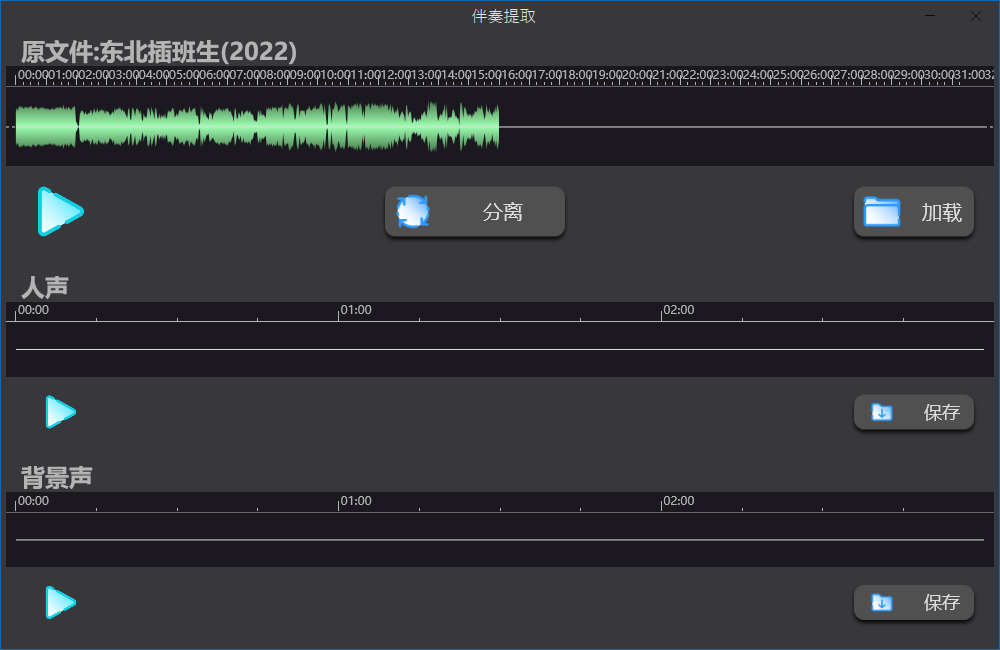
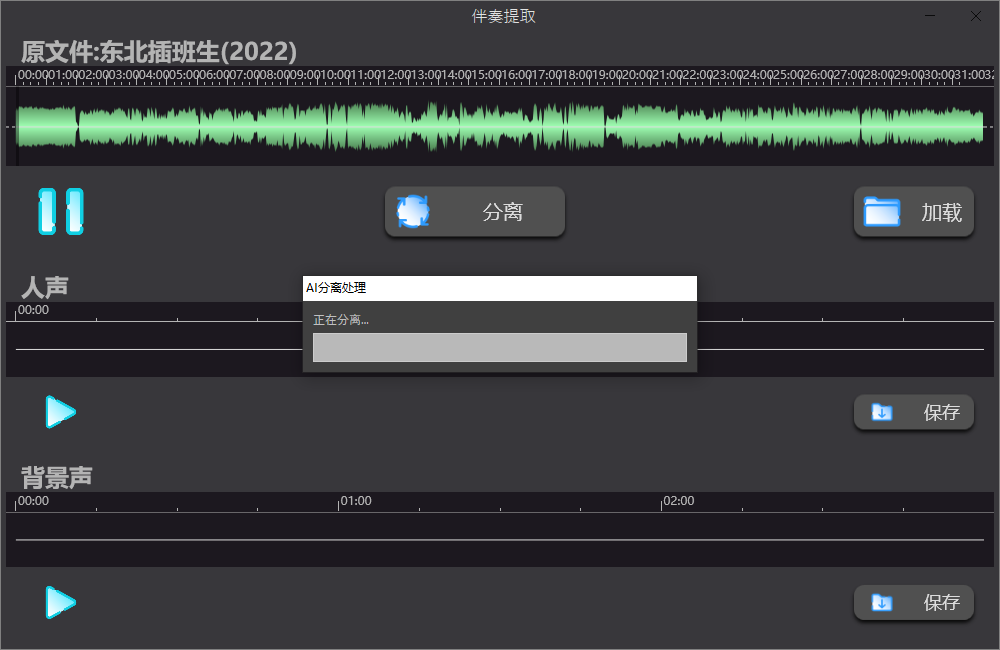
软件介绍
Soundify Vocal Remover 是一款运行于 Windows 和 macOS 桌面端的专业级音频分离工具。不同于依赖云端计算的传统在线去人声服务,Soundify 将复杂的 AI 音轨解混技术(Audio Source Separation)集成到本地设备中。它摒弃了老旧的 Center-Cut(中置声道消除)算法,能够精准识别并剥离立体声或单声道音频中的人声与乐器伴奏。凭借极简的“傻瓜式”交互逻辑与断网可用的特性,它已成为众多自媒体创作者和音频爱好者的伴奏制作神器。
核心功能
本地 AI 运算引擎:采用端侧(On-device)AI 算法进行音轨分析与分离,音频文件无需上传至远程服务器,彻底解决网络延迟问题并消除数据泄露的隐私隐患。
极速高保真分离:具备卓越的运算效率,据测试处理一首常规3分钟的歌曲仅需数十秒。分离度极高,最大限度保留了人声的频响细节与伴奏的低频下潜。
多源格式兼容:原生支持 WAV、MP3、AAC (M4A) 和 AIFF 等主流音频格式,满足从无损发烧级到常规流媒体的不同处理需求。
一键式操作逻辑:摒弃复杂的频段调试与相位反转设置,用户仅需导入原音频并点击“Separate”(分离)按钮,软件即可自动输出两条独立的音轨(人声文件与伴奏文件)。
适用人群
短视频与自媒体创作者:需要提取干净的背景音乐或人声进行二次混剪。
音乐制作人与 DJ:需要获取高质量的 Acapella(清唱)或纯伴奏用于 Remix 混音。
K歌与翻唱爱好者:难以在网络上找到冷门歌曲的官方伴奏时,用于快速自制卡拉OK音轨。
播客与采编人员:用于对带噪环境下的演讲或对话录音进行辅助降噪处理。
优缺点分析
优点:
隐私与稳定性:完全离线运行,不受网络波动限制,保护未公开版权的音频素材。
算法先进:相比传统的相位抵消法,AI 深度学习模型的引入大幅减少了分离后的“水下音”和频段缺失等数字假象。
易用性极强:学习成本几乎为零,无需掌握专业 DAW(数字音频工作站)的使用技巧。
缺点:
硬件依赖:由于在本地跑 AI 模型,处理速度会直接受限于用户电脑的 CPU 或 GPU 算力。
功能单一:目前主要聚焦于“人声/伴奏”的二轨分离(Stems 2),缺乏将鼓点、贝斯、合成器等单个乐器独立拆分(Stems 4 或更多)的高阶功能。
系统要求
Windows:Windows 10 或 Windows 11(64-bit),可通过 Microsoft Store 获取。
macOS:macOS 12.0 或更高版本,原生支持 Apple Silicon (M1/M2/M3) 芯片以获得最佳 AI 加速体验。
硬件建议:推荐配备四核及以上主频的现代处理器,至少 8GB RAM(处理高采样率无损文件建议 16GB)。
下载地址
声明:本站为非盈利性技术交流平台。所有资源均来自互联网或官方发布,版权归原作者所有。如有侵犯您的权益,请联系我们(fzxzcopy@163.com),我们将第一时间处理。