
软件截图
软件介绍
Umi-OCR 是一款运行于 Windows 与 Linux 平台的开源本地化文字识别工具。该软件基于 PyStand 框架与本地化 OCR 引擎(PaddleOCR-json / RapidOCR-json)构建,彻底剥离了对云端 API 的依赖。对于注重数据隐私、或者寻找具有极简架构的图片转文字工具的用户而言,Umi-OCR 提供了一个开箱即用、无需配置环境变量且完全免费的解决方案。它不仅弥补了常见轻量级截图应用在批量处理和排版解析上的短板,更以其出色的识别准确率和灵活的外部接口(CLI/HTTP),成为一套功能完备的本地化文本处理中枢。
核心功能
多模式文字抓取:除了内置快捷键呼出的即时截图识别工具外,另支持批量OCR识别,允许用户无上限导入主流图像格式(jpg/png/webp等)进行自动化批处理,支持完成后自动关机。
深度排版后处理引擎:针对识别后的散乱字符,应用内置的智能排版解析方案。可自动判别“多栏分段”、“单栏缩进保留”(处理代码片段)及竖排方向文本,还原符合阅读直觉的文档结构。
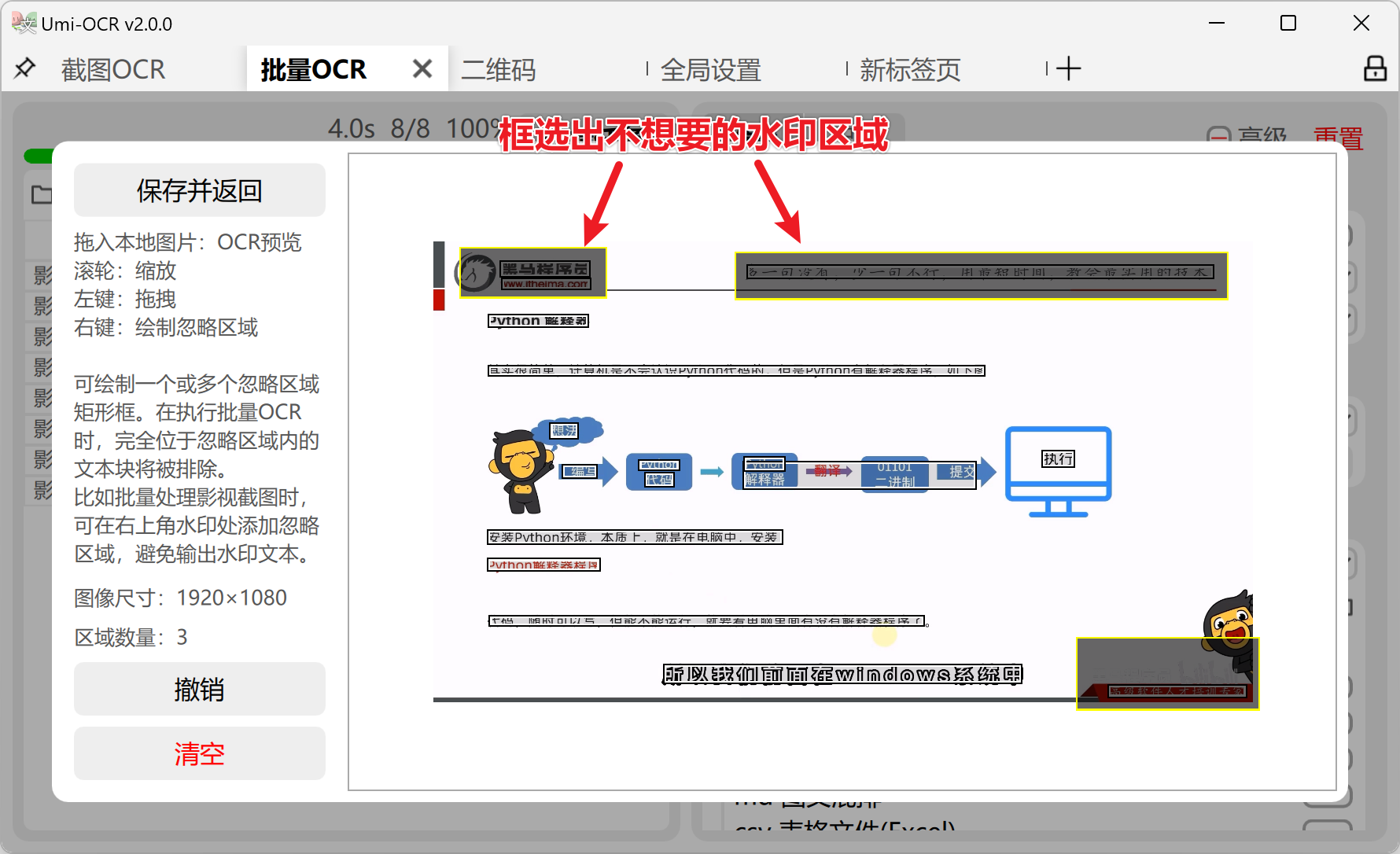
图像区域屏蔽(忽略区域):在批量图片处理或长图识别任务中,用户可通过图形化界面框选特定区域(如固定位置的水印、平台LOGO、页眉页脚),使引擎在识别过程中对该区域自动绕过,提高输出纯净度。
多格式文档提取:原生支持 PDF、XPS、EPUB、MOBI 等文档的扫描读取。既能直接剥离文本,也能将各类扫描件重构输出为带有底层文本的双层可搜索 PDF 文件。
二维码/条形码解编:内置高达19种的一维码及二维码协议扩展,支持单图多码解析与文本生成二维码的逆向操作。
适用人群
长期处在内网办公环境,有严格保密需求的企业用户及财务/法务人员。
需要将大批扫描版古籍、外文资料或文献进行数字化归档的科研工作者。
追求极致效率,需要快速提取代码图片、进行公式识别的开发者与学生。
寻求免费离线OCR工具进行大规模电子书及图文排版的自媒体编辑。
优缺点分析
优点:
极高的安全性与独立性:整个识别过程发生于本机硬件,杜绝任何外部网络发包,充分保障数据隐私。
环境免配置:打包策略优秀,自包含所有运行库与语言模型,无需预装 Python 或配置 CUDA 环境,真正做到解压即用。
灵活的数据输出:批量识别任务不仅支持 TXT 与 Markdown,更支持标准 CSV (Excel) 及 JSONL 结构化数据导出,便于后续数据清洗对接。
缺点:
算力依赖:作为本地端应用,大型文档的批量转换速度直接受制于机器 CPU 线程数及内存开销,低配设备可能出现识别瓶颈。
跨平台局限:目前原生支持 Windows x64 与 Linux x64,暂未提供 MacOS 版本的官方预编译包。
系统要求
Windows:Windows 7/8/10/11 (要求64位系统)
Linux:主流 x64 Linux 发行版(需对应运行库版本)
通用硬件建议:对硬盘/内存读取性能要求较高,建议配置 4GB 以上可用物理内存,并部署于固态硬盘(SSD)中以获得理想的并发识别速度。对于UI渲染有闪烁或错位的旧设备,需在设置中手动切换渲染器或关闭硬件加速。
下载地址
声明:本站为非盈利性技术交流平台。所有资源均来自互联网或官方发布,版权归原作者所有。如有侵犯您的权益,请联系我们(fzxzcopy@163.com),我们将第一时间处理。